Frequently Asked Questions
Should you worry that your data and IP – research data, training manuals, professional journals, medical data, meeting recordings – has been swallowed up by AI or misused internally? Yes. Compliance is a huge issue where AI is rapidly becoming a system of record.
And you’re losing money, brand protection, and market reputation as a result with lower customer engagement, regulatory fines, and consent orders that add friction to operations. That’s where Parsifer comes in. Our platform equips data owners – CIOs, Compliance Officers, and IT professionals – with a radically innovative solution to identify the use of their data by AIs, create audit trails, and provide evidence to enforce their policies, and monetize their IP.
1. What’s Parsifer about?
Parsifer equips data and IP owners to thrive in a world of AI risk. And by risk, we mean the widespread theft of copyrighted IP by AIs rampaging across the Internet. We also mean the unauthorized use of data by employees, hackers, and exploits such as bots and scrappers. Our solution is a revolutionary yet easy-to-use digital service for data governance that identifies how your information is being used by an AI model or agents, both internally and externally.
We offer three things to our customers:
A unique, proprietary Identify, Track, & Trace tool that monitors data usage & AI output
Easy-to-follow analytics and an audit trail to enforce data rights, policies, and spot security gaps
Compliance means data governance, system orchestration, the memory of what happened:
Parsifer protects artifacts and timelines.
Parsifer is an empowering technology, providing IP creators with hard data on how their work is reflected in AI systems.
2. Is the situation that urgent regarding AI exploitation of data?
AI systems – specifically, Large Language Models (LLMs) – have been built, or trained, on digital content from the Internet. Put bluntly: LLMs have pretty much swallowed up all forms of digital content, including IP under copyright and behind paywalls. And moreover, the pressure from executives is on to operationalize AI at all levels of the workforce.
Many AI companies still, remarkably, claim they do not violate copyright laws in acquiring their training content, either buying or licensing it, or relying on the fair use principle. Believe that if you like (but don’t). They also claim that they can’t track the data they use or pinpoint its source. It’s highly probable your work has been swallowed, either taken in directly by an LLM or acquired from a pirate website somewhere offshore.
Parsifer provides verifiable insight – hard evidence – to determine whether your work has been uploaded into an LLM – or multiple LLMs. The solution also works across the wider internet to check competitors and websites for pirated data.
3. Why is Parsifer important for data-driven enterprises?
It’s pretty simple: the unauthorized use or appropriation of your data degrades your ability to monetize it.
To make matters worse, the AI processing of your work – stripping it of identifying markers and chopping it up in ways not intended – often results in misrepresenting your original intent, causing reputational and brand damage, not to mention annoying the hell out of you.
This is basically a multi-billion dollar revenue grab by AI companies in violation of your rights and ability to make a living from your data and IP.
4. You appear to see American innovation in AI as the enemy?
AI has many great uses and millions of people and businesses are engaging today with LLM models to improve productivity, to learn, to make their lives better. Like many technologies, AI is a tool, neither good nor bad, but the way it’s used can be either.
Parsifer believes that data stewards and owners have the right to determine how their information is used, and that AI systems must respect that right. Most AI systems don’t provide transparency with respect to the data they use or acknowledge their sources in response to prompts. These are troubling indicators of what’s to come.
By now we have all seen how tech innovation has impacted the music industry and journalism, completely disrupting their revenue models. So, it’s natural – no, it’s essential – to be concerned with what’s happening today in the AI sector.
Consider the white papers for AI regulation recently submitted to the U.S. government by the most prominent AI companies. Draped in the logic of national security, AI companies argue that copyright laws should evolve to ensure that AI systems have more or less free access to all content scraped off the Internet, with very little consideration to how this will affect the economic realities of content creators.
It's as if your data exists only for AI commercialization with zero respect for the voices and workers that created that information over so many generations. In contrast, we at Parsifer believe data owners should retain agency and be fairly compensated for their work.
5. Parsifer is a curious name, what’s behind it?
Parsifer is a combination of Parsing and Inference, which speaks to how the technology works and how tech people think. We parse arguments or data, say, breaking down ideas or concepts into components for analytical purposes, which is where inference comes in, the interpretative act in an evaluation process. More fun to consider is that our name was inspired by the medieval tale of Parsifal, the knight searching for the Holy Grail. Parsifal is basically the OG Knight in Shining Armor, a protector. That’s kind of how we view our purpose in serving the broader community, providing them with new solutions to protect and monetize their work; restoring trust in the system.
6. How does Parsifer work?
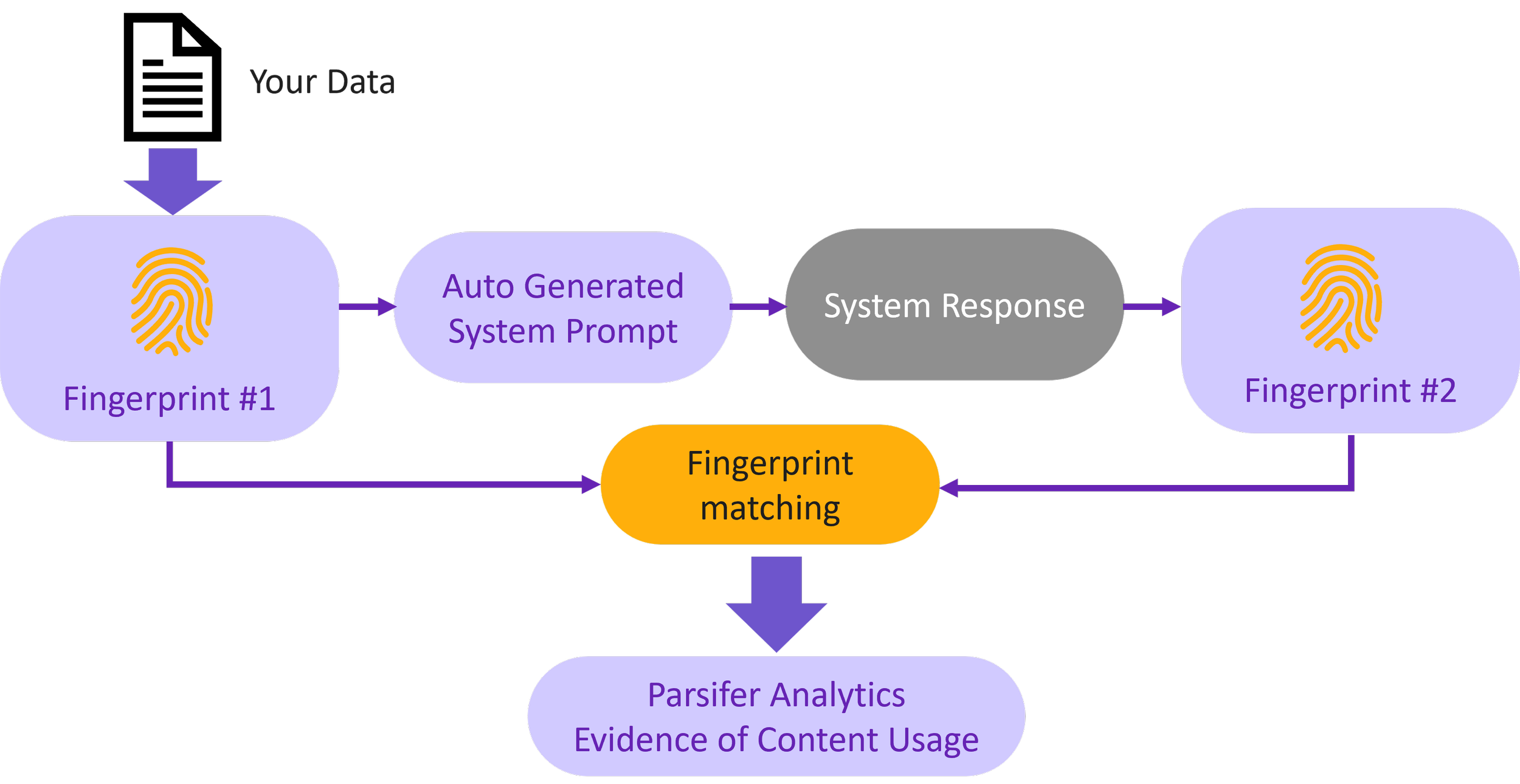
The Parsifer solution, accessed using an SaaS platform, starts by analyzing a sample of your work to generate a digital, semantic “fingerprint” of its characteristics: the unique DNA of the data. We take that fingerprint and create a prompt to query an LLM or a broader system (archive, internet, website), all towards generating a second fingerprint from the response of that query. The resulting second fingerprint either matches yours or doesn’t. Think of this process as a digital equivalent of dusting a crime scene for fingerprints. Parsifer uses a four-step process to determine whether an AI system is using specific source data:
Source data is fed into Parsifer, from which it generates a semantic fingerprint (FP#1) featuring metadata qualities that represent the source information.
A prompt is then submitted to an LLM or data repository using the metadata elements from that fingerprint.
The response data is fed into Parsifer from which it generates a second semantic fingerprint (FP#2).
The two fingerprints, FP#1 and FP#2 are compared, yielding a similarity score and probability assessment — the analytics — that the specific source content has been used and to what degree.
7. Is there a minimum word or token count to use the service?
Parsifer works with data as short as a tweet and as long as a novel. As long as there are words and text to work with, we’re there for you.
8. What is the reliability of Parsifer’s methods for matching the “fingerprints” of the source content with the output of AI systems?
For both long- and short-form text content, Parsifer has shown 90%+ fingerprint matching accuracy across the tested AIs and platforms.
9. What types of content can Parsifer evaluate?
In the beginning, we started with text. Now we are extending the fingerprinting to most types of data, media, and artifacts.
10. Why should I trust Parsifer to look after my interests?
We’re in the truth business. We believe in facts and evidence.
Parsifer is building an independent compliance service that helps data owners first and foremost – be they enterprises, SMBs, non-profits, estates, or IP funds – to monitor and manage the use of their data.
We make money through subscriptions and licensing fees to businesses and organizations that own or manage IP in the aggregate – say, a healthcare concern, a bank, or a crypto company that operates on secure data.
11. What are Parsifer’s target markets?
Our market focus today is regulated industries, such as FinTech, Banking, Healthcare, Insurance, and Government; data owners involved in legacy and forward-looking proprietary corporate data and concerned about compliance risk analysis.
12. How is Parsifer different from other solutions?
Parsifer has a patent pending, evidence-based methodology to determine whether source data has been used or uploaded into an AI system or repository. Many existing solutions in this field predate the specific challenges posed by AI systems. They include:
Watermarking— these can be stripped out by AI processing
Bot trackers and blockers— these only work at the firewall, and do not guarantee protection once the content is out on the Internet.
Enhanced network security— attempts to harden networks are still based on old solutions that cannot wholly protect content in its various forms.
Licensing agreements— both micro-licensing and more conventional models.
Litigation—there are hundreds of lawsuits targeting AI system data use.
So far, these solutions and others, while useful, only superficially dance around the deeper problem – the real technical challenge – of going inside an AI system to figure out what’s actually going on and piecing together evidence of reuse as well as theft of source content data. No one else is doing that. If you listen to the AI companies, they say it’s not possible to do what we say we’re doing.
Sorry – but it is possible. And Parsifer is a gamechanger.
13. Does Parsifer keep or otherwise attempt to monetize my data or IP?
We’re not in the business of unethically exploiting your data. If you’re an IP owner, we process the data you choose to upload through the service. From that we keep only sample information – or metadata – which identifies the provenance and digital history of your IP. We use that metadata to create the fingerprint of your unique style. We don’t save the data you uploaded. Any other reports or other data related to using the Parsifer service is kept in our system – but only you can see it!
14. Will Parsifer prevent unlicensed content appropriation?
Initially Parsifer will provide an indirect effect: the service creates evidence-based awareness that empowers data owners to pursue the most effective strategy for their business objectives. Over time, the tools and support provided by Parsifer will mitigate and alert IP owners when an AI bot or other agents try to appropriate data outside of corporate policies and licensing protections.
15. Can I see a demo?
You can sign up for a demo at this scheduling link: Calendly
16. How do I sign up?
Reach out to one of our representatives at info@parsifer.com and contact us.
17. What subscription tier do I pick for my needs?
If you are an Enterprise or service provider, contact one of our representatives at info@parsifer.com.
18. Who is behind Parsifer?
Parsifer was founded by Sharon Bolding’s (PhD) vision. Sharon is the CEO and a successful serial entrepreneur, and an expert in machine learning, AI, and linguistics. It’s her unique perspective that underlies Parsifer’s own intellectual property.